This week, we break down the operational cycle of a standard AI computer vision system and how design and architectural decisions impact ongoing operational costs associated with deploying and scaling AI computer vision across a retailer’s portfolio of stores.
In our last blog post, we explored the hardware, software, and development costs of production-ready computer vision and how AI system design can impact the Bill of Materials (BOM). However, while the cost of building and provisioning a computer vision-based retail solution certainly needs to be carefully considered, especially in light of how those costs might compound as a retailer scales to include more and more stores, the other cost vector to consider is how much the solution costs to operate and maintain.
Much like production costs, such operational costs are heavily influenced by system design as well, and often have a greater impact on the total cost of ownership of running a production-ready system. Many of the computer vision deployment costs we previously highlighted carry over as operational costs—data storage in particular comes to mind, depending whether you’ve elected to use a cloud-based solution or an on-prem one.
The most critical ongoing costs, however, relate to the ongoing training and upkeep of the AI model itself. To fully explain these costs, it’s helpful to break down the operational cycle of a typical computer vision system, particularly as it relates to how the model is trained, deployed, scaled, maintained, validated, and updated.
Computer vision image types
One of the most widely misunderstood concepts within computer vision involves the images needed for an operational computer vision system and how they’re used. Before we dig into the operational cycle, we need to explain the different types of images needed and how they are used.
Training Images
First and foremost, any AI model needs a large set of images that are used to train the model for the specific task the system will be used for. In retail, a good example would be product recognition for checkout, self-checkout, or on-shelf inventory management.
Validation Images
In addition to training data, you’ll need a set of images that are used to validate how well the AI model operates. In this case, we’re specifically trying to determine if the AI model can “generalize” appropriately, i.e., can the model work accurately on images that it has not trained on and has never seen before. These images, while similar to those used in the AI model training, explicitly need to be images that are kept separate and are never used for model training. If you were to use the same images the model was trained on, all you would be doing was validating identical matching capability, rather than AI-driven computer vision.
Enrollment Images
In the case of product recognition, the next set of images are product enrollment images. This is the set of images that are loaded into the AI model for the model to search against. For product recognition use cases, this might be your entire product catalog, for example, or a subset of that catalog. How many images you need for enrollment will vary depending on what the computer vision system requires (more on this later).
Matching Images
The final set of images are the search queries themselves. In production, these are the images that are captured in the moment that the model is asked to find or match against the set of enrolled images. For example, during checkout, images of what’s in a customer’s cart or in the scanning area are being captured and sent back to the model for identification. Matching images are also known as “model inference,” which is when a trained machine learning or AI model uses new data to make predictions or classifications.
Typical computer vision operational cycle
Now let’s dive into a typical operational cycle to understand how AI computer vision product recognition models get deployed and how these different images are used.
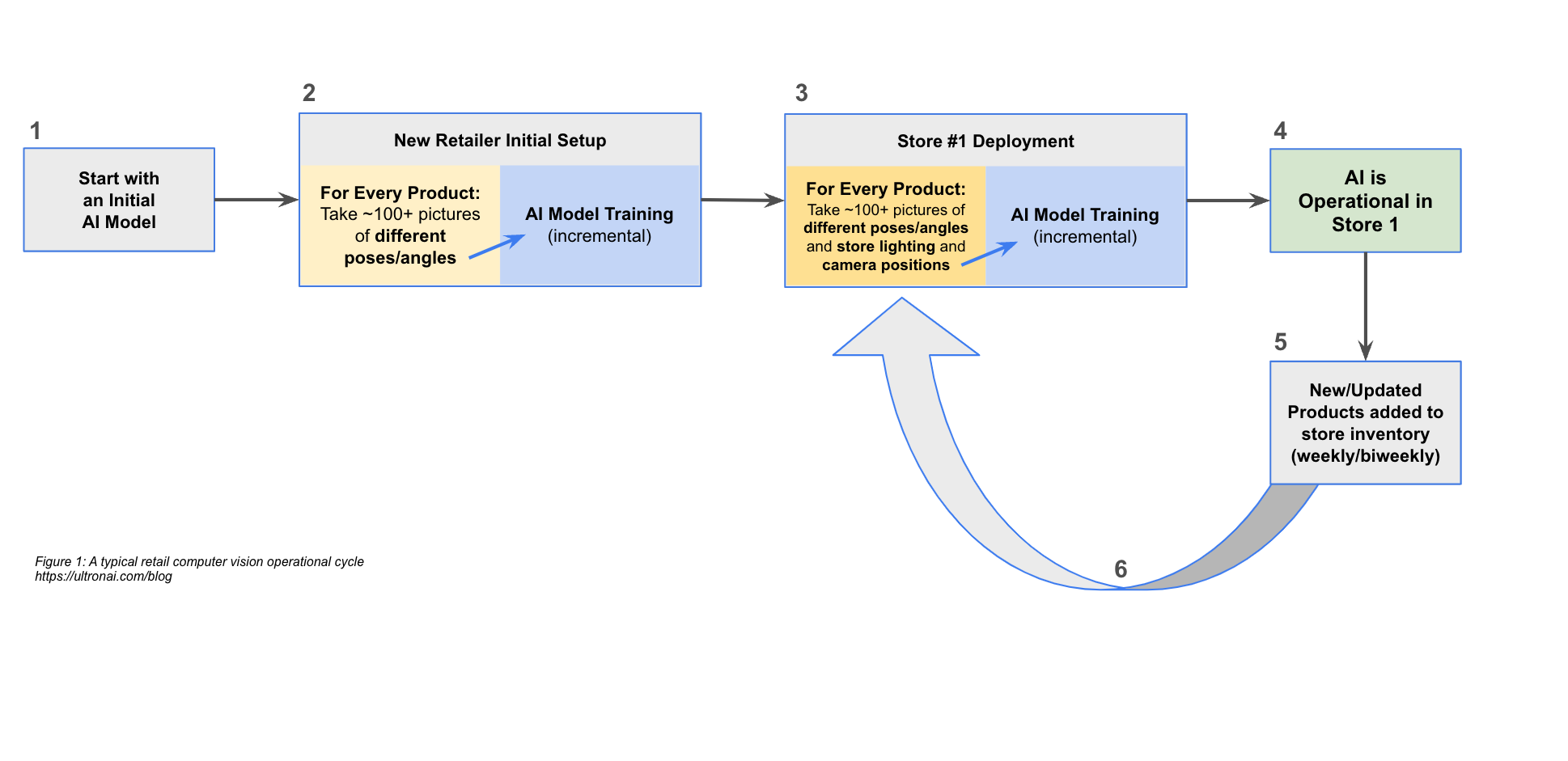
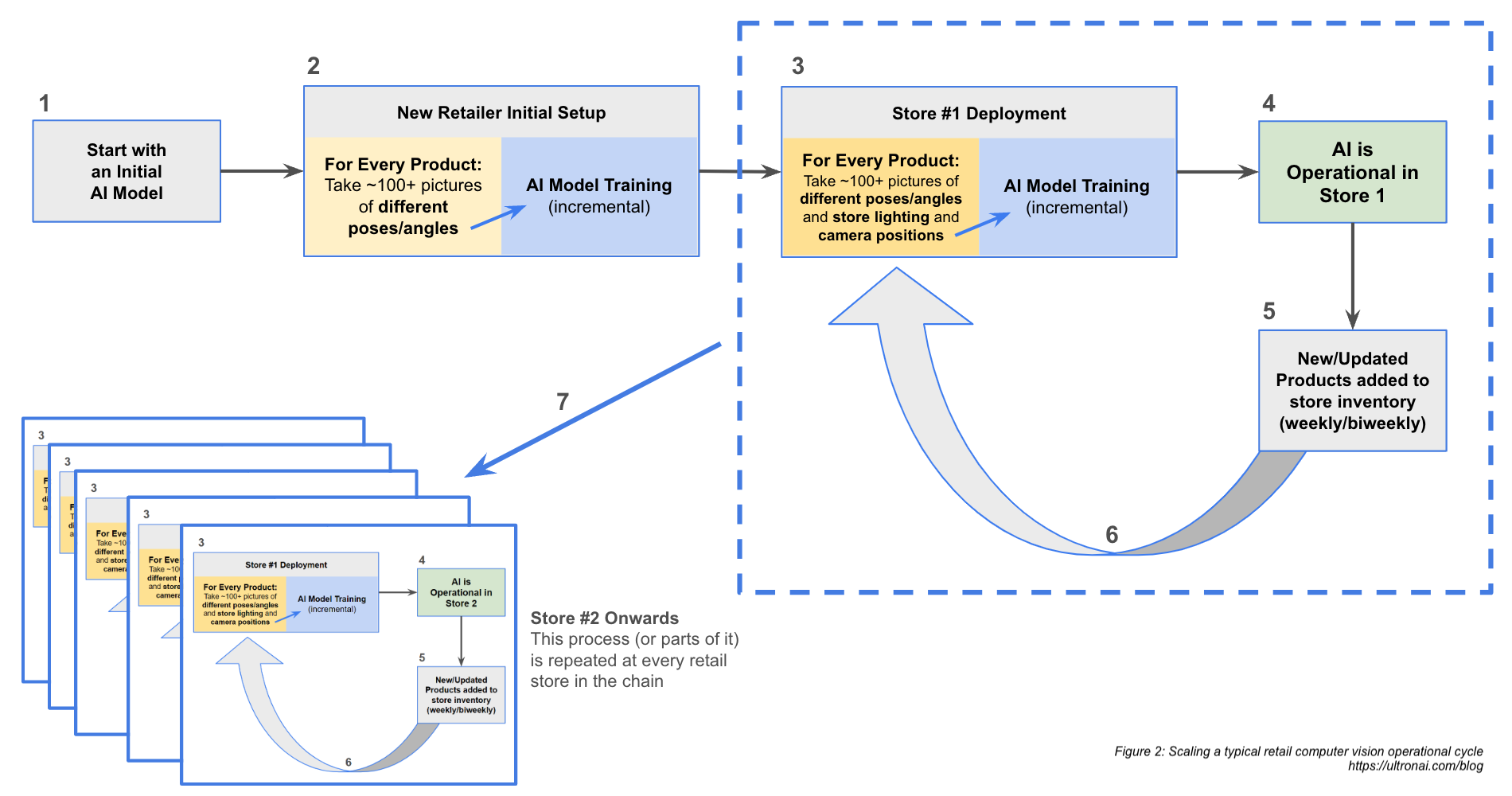
Figure 1: A typical retail computer vision operational cycle
Step 1: The initial AI model
Operationalizing a typical AI computer vision system starts with an initial AI model (Figure 1, Box 1). This AI model may be a pre-trained model such as EfficientNet, ResNet, or YOLO, or it could be a proprietary one. Most computer vision solutions start with a pre-trained model to reduce effort and time to market.
Step 2. Customizing the model to the retailer
Regardless of what is selected, the initial AI model then typically needs to be trained to meet the needs of the specific retailer and their products. This process commonly begins by feeding the model a training data set, which can often include approximately 100+ images of each individual product (Figure 1, Box 2). Such images might come from a variety of sources, such as existing digital content and catalogs or manually collected and labeled. For many computer vision models, this large volume of pictures includes a set of different poses and angles for each product and is needed in order to help the computer vision system better match the product in production, regardless of the angle or pose captured by the camera when it’s deployed at a store.
The product images are first run through a quality assurance (QA) process wherein the images are reviewed, likely by a human, to ensure they are correctly segmented and labeled, and, if needed, categorized. This process is critical to preventing the model from being trained on bad data, which can be as seemingly irrelevant as ensuring that the image is cropped correctly so that the model doesn’t mistake background images as part of the product itself.
Following QA, these images are used to train, validate, improve, and revalidate the AI model in an incremental manner. Once the training of the AI model is complete, it undergoes verification (using verification images as defined above) to ensure the training was successful and did not introduce errors. This completes the initial setup.
Step 3. Initial deployment of the model
Once the model has been set up and verified, the system can move into deployment. Most commonly, this step involves yet more 100s of pictures of those same products within the store itself (Figure 1, Box 3). Many computer vision models require this additional training set of images to account for the store’s unique environmental conditions such as lighting or the positioning angle of the production-use cameras in the store.
Just like in Step 1, these pictures need to undergo the QA and verification processes to ensure the additional training was successful and did not introduce new errors.
Step 4. Production operations of the model
At this point, the model is considered production ready and can be used operationally in the first store (Figure 1, Box 4).
Step 5. Required adjustments to the model
Of course, model training isn’t a one-time thing. In normal retail operations, inventory shifts constantly as brand new products are brought into the catalog or existing products change packaging. Every time this happens, the model becomes less accurate until it can be adjusted to account for the changes. Depending on the volatility and size of the store catalog, this could be as often as biweekly, weekly, or even semi-weekly (Figure 1, Box 5).
Step 6: Maintaining the model during inventory and packaging changes
When product catalog changes are introduced, a typical computer vision model requires the retailer to incrementally train the model again, using the same picture-taking and model training process described in Step 3 (Figure 1, Box 3), including taking 100+ pictures, training the model, and verifying the model training. To keep the AI model current and accurate, this process loop is effectively happening constantly, adding operational overhead to manage and execute the process.
Step 7. Scaling the model beyond the first store
Of course, Steps 3-5 outlined above refer only to deployment in a single store. As retailers look to deploy widely across all their stores, this same process needs to be repeated for each store (Figure 2).Lighting and camera positioning in each retail store will be different, and therefore the operational time and costs of the initial deployment and operations of the model multiply with the addition of each store without being able to meaningfully benefit from previous training.
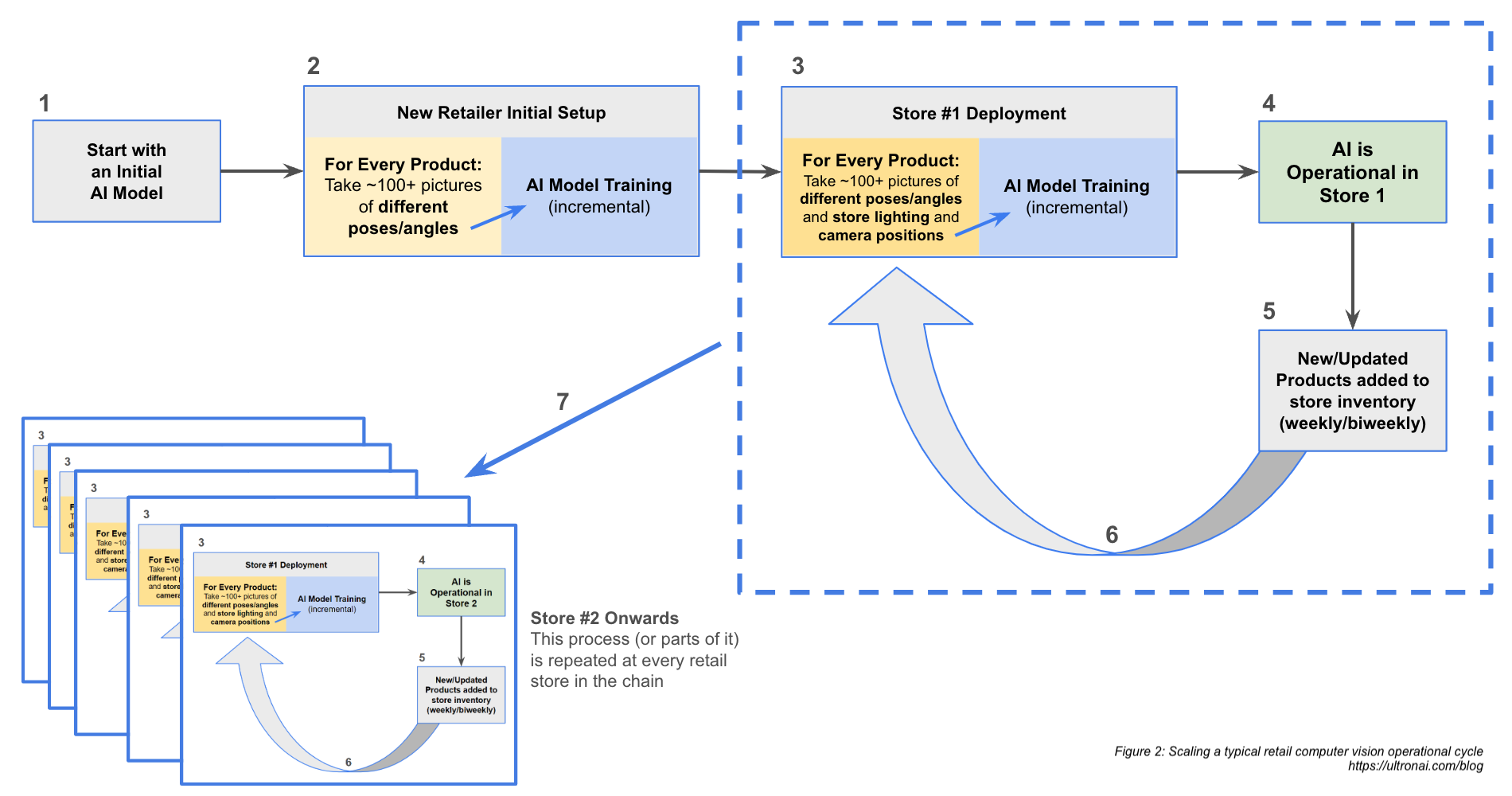
Figure 2: Scaling a typical retail computer vision operation
Inefficiencies in the typical computer vision operational cycle
You’ll note that in our image definitions outlined in the previous section, we highlighted images needed for enrollment but have not highlighted them here. That’s because in many typical retail AI computer vision systems, image enrollment, in essence, becomes model training. The model is trained on the images of the products it needs to enroll.
Unfortunately, such an approach is both costly and time consuming due to the hundreds of images required per product, and as stated earlier, it also makes it more difficult for the model to generalize, i.e., to be able to accurately interpret and identify new images based on the trained data set. This is not, unfortunately, how deep learning models should be built; however, it can be significantly easier to manage accuracy, albeit at the cost of a lot more training and the inability for the computer vision model to generalize.
Cost impact
Savings due to economies of scale are lost in the computer vision operational cycle we’ve outlined here because of the way it has been designed. Indeed, those costs are compounded. In addition to the time-consuming collection of product images needed for AI model training, the actual training and verification steps are both slow and expensive for most deep learning models. By electing to train (and arguably, overtrain) the model with hundreds of images of each product, the model effectively learns to do a simple visual matching exercise rather than employ true AI. The inability to generalize makes it difficult for the system to accurately recognize an image that is askew, obstructed, or poorly lit in comparison to the images it has been trained on.
This method, while extremely common in the world of retail computer vision, is effectively a brute-force approach to building an AI model for product recognition. It’s a ton of work to manage and maintain, and creates significant challenges in terms of operating an accurate model at scale.
From a cost perspective, this typical operational cycle balloons labor and data costs, as well as introduces opportunity costs. On the labor side, this approach requires an equal amount of effort to be put into tuning the model for each individual store without the efficiencies typically gained through economies of scale. When multiplied across both the number of stores and the incremental requirements due to product catalog changes, these costs grow exponentially. In addition, the amount of data (and its related storage and processing costs) required has gone through a similar exponential increase. Finally, the effort required to introduce a new product, may mean a delay between the introduction of the product and the ability for the computer vision system to recognize it, resulting in either a poor user experience or lost revenue from the delay.
This cost expansion is a direct result of the model training outlined above—by tuning the model toward specific product matching rather than generalization, this approach creates additional work to maintain and manage the model against a changing product catalog. That inability to generalize can also create more accuracy and user experience frustration due to unexpected changes to store lighting, positioning, and customer behavior when interacting with the system.
An extreme example of this was Amazon’s “Just Walk Out” technology, which was reportedly powered by 1,000 human video reviewers overseas, likely due to an inability to trust the accuracy of the model.
Understanding the relationship between design and costs
As retailers move computer vision from the lab to the streets, costs are a critical component of their calculus. However, it’s critically important to understand all of these costs in the early stages of the development cycle rather than leaving them for later.
As we’ve outlined here, there are a number of ways in which operational costs for running a computer vision system in retail can balloon. By taking them into account early in the process, retail solution providers can think critically about which areas to calibrate for and where to make trade-offs between accuracy, speed, cost, and scale. Without that holistic analysis early in the process, retailers and retail solution providers run the risk of investing countless hours and dollars into a solution that may end up being economically unfeasible to scale.
In our next blog post, we’ll discuss ways this process can be improved upon by using a different approach to training, enrollment, and deployment.


